EAP 7 とPicketLinkとKeyCloak について
JBoss EAP 7.0 のリリースノート( 7.0.0 Release Notes - Red Hat Customer Portal
)によると、全てのPicketLink関連のモジュールはDeplicated (サポートはされるけど、機能拡張は無し、また今後のリリースではDropされる)となったようです。
さらに、以下の機能についてはUnsupportedとなったようなので、注意しておいたほうが良いですね。
PicketLink
- PicketLink IDM
- PicketLink IDM subsystem
- STS Client Pooling feature of PicketLink Federation
- PicketLink JEE (CDI Security)
その代わり、EAP7では、JBoss KeyCloak Client Libraries for EAP 7/ KeyCloak Serverというのが登場します。
と、ここまで書いているうちに、Red Hat Single Sign-On 7.0 (以下、RH-SSO)なるものがリリースされていました。(あ、今日は2016年6月20日の月曜日なので、おそらく先週くらいに出たものだと思います。)
これはレッドハットのカスタマーポータルからダウンロード出来るようになっています。ダウンロードサイトに行けば分かるのですが、RH-SSOは以下のように使いたい機能毎に分けて、ダウンロード出来るようになっています。
- Red Hat Single Sign-On 7.0.0 Server
- Red Hat Single Sign-On 7.0.0 Client Adopter for JBoss EAP 6 / 7
- Red Hat Single Sign-On 7.0.0 JavaScript Adopter
- Red Hat Single Sign-On 7.0.0 SAML Adopter for JBoss EAP 6 / 7
一番上の「Server」というものが所謂SSOサーバーで、SAMLであればIdPとして使うものとなります。zipファイルとして提供されており、任意の場所に解凍するだけで利用出来るようです。
ということは、それ以外の、XXXX Adopterというものを使うことで、色々なアプリケーションをRH-SSO Serverと組み合わせて、認証させることが出来るようです。
Ansible Tower をインストールしてみる
インストールの方法については、以下のマニュアルに記載があります。
http://docs.ansible.com/ansible-tower/latest/html/quickinstall/prepare.html
yum install http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
おっと、いきなりepelでございますか。epelを入れたら、いつものようにyumコマンドでansibleをインストールします。
yum install ansible
これだけで、Ansibleのインストールは完了です。この後、Ansible Towerのインストールを行っていきます。
wget https://releases.ansible.com/awx/setup/ansible-tower-setup-latest.tar.gz
そしてtar.gzを適当な場所に展開して、展開したディレクトリにcdしておく。
cd ansible-tower-setup-2.4.5/
configureスクリプトがあるので、それを実行。ここでいくつか質問をされるのでそれに答えていきます。
質問される内容は、
- インストール先のマシン(HA構成も組めますが、今回はlocalhostでシングル構成にしました)
- データベースの場所。(今回はlocalhostに全部いれてしまう構成にします)
- Ansible Tower管理者のパスワード
- Muninのパスワード
これだけです。
[root@rhel72-docker-test ansible-tower-setup-2.4.5]# ./configure ------------------------------------------- Welcome to the Ansible Tower Install Wizard ------------------------------------------- This wizard will guide you through the setup process. PRIMARY TOWER MACHINE Tower can be installed (or upgraded) on this machine, or onto a remote machine that is reachable by SSH. Note: If using the High Availability features of Tower, you must use DNS resolvable hostnames or IP addresses (do not use "localhost"). Enter the hostname or IP to configure Ansible Tower (default: localhost): Installing Tower on localhost. DATABASE Tower can use an internal database installed on the Tower machine, or an external PostgreSQL database. An external database could be a hosted database, such as Amazon's RDS. An internal database is fine for most situations. However, to use the High Availability features of Tower, an external database is required. If using an external database, the database (but not the necessary tables) must already exist. Will this installation use an (i)nternal or (e)xternal database? i PASSWORDS For security reasons, since this is a new install, you must specify the following application passwords. Enter the desired Ansible Tower admin user password: Enter the desired Munin password: REVIEW You selected the following options: The primary Tower machine is: localhost Tower will operate on an INTERNAL database. Are these settings correct (y/n)? y Settings saved to /root/tmp/ansible-tower-setup-2.4.5/tower_setup_conf.yml. FINISHED! You have completed the setup wizard. You may execute the installation of Ansible Tower by issuing the following command: sudo ./setup.sh
あとは、同ディレクトリにあるsetup.shを実行すればインストールは完了です。Ansibleは/にマウントされたディスクが10G以上空いていないいけませんので、注意が必要です。
インストールが完了したら、ブラウザでインストールしたサーバーの名前(またはIPアドレス)を指定するとAnsible Towerの画面が表示されます。ユーザー名/パスワードを聞いてきますので、admin/あなたの設定したパスワード と入力することでログインが出来ます。
これで終わりではありません。Towerへのログインが成功すると、ライセンス情報を入力するように言われます。

「Get a Free Tower Trial License」というボタンを押すと、検証ライセンスが入手出来るページに飛びます。

今回は「FREE TOWER TRIAL - UP TO 10 NODES」のほうで試してみました。必要な情報(名前やメールアドレスなど)を入力してSubmitすると、ライセンスキーがメールで届きます。

最後に届いたライセンスキーを設定して、Submitすればセットアップ完了です!
JBoss EAP 7.0 がリリースされていました
Jboss EAP 7.0 が正式にリリースされておりました。目立ったアップデートだけ、メモっておきます。
新機能などについてはリリースノート(7.0.0 Release Notes - Red Hat Customer Portal)に記載されていましたので、その中から主だったところを抜粋。(詳細は上のリンク先を読んでください。)
互換性など
- EJB、JMS、WSなどのクライアントはそのまま動作するでしょう
- EAP7のドメイン管理者はEAP6のホスト/サーバーを管理することが出来ます
- EAP5、EAP6のバージョンが最新であれば、EAP7上のEJBのリモート呼びだしが可能です
- JMSがHornetQからActiveMQ Artemisへ変更
管理系機能
- 管理コンソールのアップデート。より使い易く、より大きなドメイン設定に対応
- 管理コンソールの左下に詳しい製品バージョンが表示されるようになった
- CLIを使うと、設定変更の履歴をみることができるようになった
- ロギング拡張。管理コンソールから参照可能。またサブシステム毎に設定等可能となった
- CLIにオフラインモードが追加された
- Picketlinkフェデレーションのサブシステムを利用する際、管理コンソールから設定することが可能となった
- インストレーション・サマリの作成が出来るようになった
- 標準プロファイル(default, HA, Full など)をベースにして、カスタム・プロファイルをCLI/管理コンソールから作成出来るようになった
- ドメインにおいて、階層型のプロファイルを使えるようになった
スケーラブルなWebサーバー(Undertow)
- NIOを使った高速でスケーラブルなWeb サーバーを搭載。サーブレット、非同期サーブレット、WebSocketなどに対応
- Undertowはロードバランサとして利用することも可能
- EARファイル内部の複数のWAR間にてHTTPセッションを共有することが可能となった
Java EE 7 対応
- Batch 1.0, JSON-P 1.0, Concurrency 1.0, WebSocket 1.1, JMS 2.0, JPA 2.1, JCA 1.7, JAX-RS 2.0, JAX-WS 2.2, Servlet 3.1, JSF 2.2, JSP 2.3, EL 3.0, CDI 1.2, JTA 1.2, Interceptors 1.2, Common Annotations 1.1, Managed Beans 1.0, EJB 3.2, Bean Validation 1.1
Java SE 8
- Java SE 8 以降が必要となります。
クラスタリング
JCAとデータソース
- JGroupsをベースとしたDistributedWorkManagerの実装のサポート(Tech Previewのみ)
- JCAコネクションマネージャの拡張
- データソースに対するキャパシティポリシーが設定出来るようになった
- JDBCコネクションプールからコネクションを取得するとき、戻すときに、ステートメントを実行出来るようになった
Java EE セキュリティマネージャ
サスペンド/グレースフルなシャットダウン
- 新規リクエストは受け付けず、仕掛り中の処理は中断しないようなシャットダウンが出来るようになった
TCPポートの削減
- EAP7では、使用するTCPポートが2つになりました(減りました)
IIOP
- jacORBからOpenJDK ORBへと実装が変更されました
バッチ拡張
旧サブシステムからマイグレーションするためのCLI
- EAP6でしか使えないサブシステムの設定をマイグレーションするための用意があります
EAP Natives / Apache Web Serverの配布方法の変更
- AIOネイティブ:EAP7に含まれるようになりました。
- Apache HTTP Server:(新しい)JBoss Core Servicesに含まれます
- mod_cluster/mod_jk:(新しい)JBoss Core Servicesに含まれます
- JSVC:(新しい)JBoss Core Servicesに含まれます
- OpenSSL:EAP 7 からは含まれません
- tcnatives:EAP 7からは含まれません
JBoss BPM Suite でビジネスプロセスの再デプロイをする
デフォルトでは、Business Centralを使ってビジネスプロセスを修正して再デプロイしようとすると、 「既にデプロイ済みです」と言われてしまって、再デプロイを簡単に行うことが出来ません。
本番環境では これで良いと思いますが、テスト環境など、サクサクと再デプロイを行って動作確認をするような環境では少々不便です。
これを回避するためには、設定ファイル(standalone.xmlなど)に、以下の設定を入れてやると再デプロイが可能となります。
<system-properties>
<property name="org.kie.example" value="true"/>
<property name="org.kie.override.deploy.enabled" value="true"/> <==== この行★
<property name="org.jbpm.designer.perspective" value="full"/>
<property name="designerdataobjects" value="false"/>
</system-properties>
テスト環境などでは入れておくと良いでしょう。
Java EE 7 のBatch を試してみる(その1)
今回は、Java EE7 の新機能であるBatchを試してみます。 新しい機能ですので、ゼロから全てを作成していくのは大変なので、まずは、開発環境(IDE)を準備しましょう。
以下の場所からダウンロードしてインストールしましょう。色々なバージョンを選ぶことが出来ますが、Java EE 7 の機能を試したい場合は、9.0.0以上のバージョンを選ぶようにしましょう。
JBoss Devloper Studio のインストールについては今回は割愛。
JBoss Developer Studioで開発(コンパイル等)をする際は、Java EE 7 関連のライブラリを参照する必要があります。というわけで、JBoss Developer Studioと同じマシン上に、JavaEE7 に対応したJBoss EAP 7もあわせてインストールしておくとその後の作業が楽です。
そもそもですが、jBatchってなんのためにあるのでしょうか。バッチ処理くらい今までもJavaで書いてきたし、Javaで適当なプログラムを書いてcronとかで呼び出せばいいじゃん、とそんな感じに思う人もいるかもしれません。がっ、考えてみれば、そういった工夫は、皆がそれぞれの方法で独自に編み出して、人の数だけ方言が出来上がっているとも言えます。こうした状況は、本当にバッチ処理に必要とされるエッセンスをまとめて、皆が使い易い形でフレームワークにしてしまえば、皆が幸せになれるんじゃないか、というところに起源があるようです。(ワタクシ調べ)
とにかく、Java EE7 の中で標準化されて、これを皆が使えるようになれば、そこで出来上がったバッチ処理のプログラムは、正確で、高性能で、読み易く、メンテナンス性が高く、ポータビリティの高いものとなるはずです。
というわけで、まずは、Batchというものを(これ以上は無いっていうくらい)超簡単に作ってみようと思います。
最初に言っておきますと、Java EE7 のBatchの作り方の基本は、以下のとおりです
- バッチ処理を行うJavaクラスを作成する(データ読み込み用、データ処理用、データ書き出し用、の3つ)
- 上でつくったJavaプログラムが実行される順序などを、別のジョブとしてXMLファイルに定義する。(このXMLファイルは「JOB XMLファイル」と言われたりします)
- ジョブを呼び出す(startさせる)入り口を作る(EBJでもJSPでもJAX-RSでもなんでも良いのです。規定もありません)
- 上を全部纏めて、WARファイルにパッケージングする
- WARファイルをJava EE7 対応のアプリケーションサーバーにデプロイして、ジョブの入り口を実行する(上でいうJSPとかEJBなど)
というだけなら簡単。でも実際にやってみると、なにをどこに置いたら良いのか分からない。だけど実際は、どこから作ったら良いのか分からないということだらけですよね。
ですので、今回は、いきなりゴールというか、「要するにこういう形のWARを作ればBatchは動かせる」というパッケージ構成をご紹介して、次回に続けようと思います。
-------------------------------------------------------- meta-inf/manifest.mf meta-inf/ web-inf/ WEB-INF/classes/ WEB-INF/classes/META-INF/ WEB-INF/classes/META-INF/batch-jobs/ WEB-INF/classes/META-INF/batch-jobs/SimpleBatch.xml WEB-INF/classes/mybatch/ WEB-INF/classes/mybatch/batchlet/ WEB-INF/classes/mybatch/batchlet/MyFirstBatchlet.class WEB-INF/classes/mybatch/chunk/ WEB-INF/classes/mybatch/chunk/SimpleProcessor.class WEB-INF/classes/mybatch/chunk/SimpleReader.class WEB-INF/classes/mybatch/chunk/SimpleWriter.class WEB-INF/lib/ WEB-INF/web.xml startBatch.jsp --------------------------------------------------------
案外、見慣れたパッケージの構成ではないでしょうか。赤、青、緑で色を付けてあるところが大切です。
赤色の「SimpleBatch.xml」というファイルが、どのような順序で処理が実行されるのか、というようなジョブの定義づけを行っている「JOB XMLファイル」です。ファイル名は任意です。ですが、配置場所はこのフォルダでなければなりません。
青色のクラスファイルがバッチ処理の実体です。Batch用のインターフェースをimplementsして作りますが特に難しいところは無いと思います。
緑色のJSPは、ジョブを呼び出す(startさせる)、入口的な部分です。今回はJSPで作りますが、EJBでもServletでもなんでも良いです。
次回(が本当にあるのならば)は、(どちらもまだベータ版かもですが)JBoss Developer Studio 9.0.0 とJBoss EAP 7.0 を使って実際にBatchを作成して、動かしてみるということをやってみたいと思います。
Jboss EAP 7.0.0 beta を触ってみる(インストール編)
そろそろEAP 7x のベータ版でも触り始めようかと思います。おそらく、サーバーを起動するまでのところは、これまでと同様に、とても簡単でしょうから、サクサクと進めてみます。
JBoss EAP のバイナリは以下からダウンロード可能です。7.0.0 Beta は約150MbのZIPファイルでした。
あらかじめ、java などはインストールしておく必要はありますが、それらが既に整っている環境であれば、ダウンロードしたZIPファイルを適当な(あなたのお好みの)場所に展開するだけでインストールは完了です。
私はDockerコンテナでCentOS上で、以下の場所に展開しました。
[root@26d242beb516 jboss-eap-7.0]# pwd /root/jboss-eap-7.0
これでインストールは完了ですから、いつものように、./bin/add-user.sh コマンドで管理ユーザーを作成したあと、./bin/standalone.sh スクリプトでサーバーを起動します。相変わらず、あっという間に起動しますね、JBossは。
上述のとおり、今回はDockerコンテナを使って起動しているため、外からアクセス出来るように、どのTCPポートが使われているかを確認しておきます。
[root@26d242beb516 jboss-eap-7.0]# netstat -an Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:9990 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN tcp 0 0 172.17.0.2:37296 150.65.7.130:80 TIME_WAIT tcp 0 0 172.17.0.2:59040 203.178.137.175:80 TIME_WAIT tcp 0 0 172.17.0.2:59038 203.178.137.175:80 TIME_WAIT Active UNIX domain sockets (servers and established) Proto RefCnt Flags Type State I-Node Path unix 2 [ ] STREAM CONNECTED 31391 unix 2 [ ] STREAM CONNECTED 38431
上述のように、9990と8080の二つのポートが使われているだけのようです。(少くともデフォルトでは。)
というわけで、DockerコンテナとしてJBoss EAP 7.0.0 Beta を使う場合は、この二つのポートをマッピングしてやれば問題なく利用できますね。
具体的には以下の要領です。
[基本] # docker run -it -p 9990:9990 -p 8080:8080 daijik/mycentos:eap700b /bin/bash bashに入ったら、 # /path/to/jdv/bin/standalone.sh -b 0.0.0.0 -bmanagement 0.0.0.0 と起動する。
[直接EAPを起動する] # docker run -it -p 9990:9990 -p 8080:8080 daijik/mycentos:eap700b /root/jboss-eap-7.0/bin/standalone.sh -b 0.0.0.0 -bmanagement 0.0.0.0
Ansible でBIG-IPを設定してみた
早速、AnsibleからBIG-IPを設定してみる実験をしてみました。まぁ、、、普通に動くんでしょうけど、やっぱり、実際に動かしてみるのが一番理解が深まります。
OSは適当なCentOSを用意して、yum install ansible でansibleをインストールします。以下、念のため、ansibleのバージョンです。
[daijik@centos-docker-test ~]$ ansible --version
ansible 1.9.4
configured module search path = None
Ansibleでは管理対象とするサーバーは/etc/ansible/hostsに記述するので、以下のように、管理対象とするBIG-IPのホスト名(または管理用IPアドレス)を追加しておきます。
因みに、今回の実験ではBIG-IPの仮想アプライアンスをKVM上で動かしてやってみました。サクサク動きますし、日頃からLinuxを使っている方にとっては、とても取っ付きやすいと思います。BIG-IPは期間限定の評価版などがあります。以下のURLから入手可能です。
https://f5.com/jp/products/trials/product-trials
「/etc/ansible/hosts」
# This is the default ansible 'hosts' file. # # It should live in /etc/ansible/hosts # # - Comments begin with the '#' character # - Blank lines are ignored # - Groups of hosts are delimited by [header] elements # - You can enter hostnames or ip addresses # - A hostname/ip can be a member of multiple groups # Ex 1: Ungrouped hosts, specify before any group headers. green.example.com blue.example.com 192.168.100.1 192.168.100.10 [bigip] 192.168.122.95
尚、Ansibleは管理対象とするサーバーへSSHログインを行います。その際、パスワードをつかったログインも可能ですが、本格的な自動化のためには、公開鍵をつかったSSHログインが出来るようにしておくのがベターでしょう。
/etc/ansible/hostsファイルの編集が出来たら、pingモジュールを使って、疎通確認をしておきましょう。
「pingモジュールでテスト」
[daijik@centos-docker-test ~]$ ansible bigip -m ping
192.168.122.95 | success >> {
"changed": false,
"ping": "pong"
}
うまく疎通出来ているようです。
この先の作業はplaybookを使います。 たとえば、上のコマンドをplaybookにすると以下のような感じになります。
「pingのplaybook化」
--- - hosts: bigip #対象を指定。allは全ホスト remote_user: daijik #ここで特に指定しない場合、ansibleを実行したサーバと同じ tasks: #実行するtaskを以下に指定 - name: pingしてみる #taskの名前 ping:
そして、このplaybookを実行してみます。
[daijik@centos-docker-test ~]$ ansible-playbook myplaybook.yml
PLAY [bigip] ******************************************************************
GATHERING FACTS ***************************************************************
ok: [192.168.122.95]TASK: [pingしてみる] ******************************************************
ok: [192.168.122.95]PLAY RECAP ********************************************************************
192.168.122.95 : ok=2 changed=0 unreachable=0 failed=0
期待通り、BIG-IPとの疎通確認が出来ているようです。
さて、ここまで準備が出来れば、実際にBIG-IPに対して色々な命令が送れるはずです。色々な機能が実装されているようですが、今回は分かり易いユースケースとして、以下の内容を試してみます。
- 負荷分散対象とするサーバープールの設定
- 負荷分散アルゴリズムの設定
- 設定した内容の一括削除
他にもいくつか出来ることはありそうだけど、、、とりあえず、こんだけ。早速、1のシナリオを実現するための、playbookを作ります。
サーバープールの詳細ですが、以下のような内容にしてみようと思います。
- ansible-poolという名前のサーバープールを作成する
- その中に、3つのサーバーのIPアドレス:ポートを登録する(192.168.150.10:80、192.168.150.20:80、192.168.150.30:80)
- 負荷分散のアルゴリズムは、least_connection_memberを設定する。TCPのコネクション数が少ないサーバーに転送する仕組みです。
負荷分散対象とするサーバープールの設定(my_bigip_create_pool.yml)
---
- hosts: bigip
tasks:
- name: プールを作成
local_action: >
bigip_pool
server=192.168.122.95
user=admin
password=admin
state=present
name=ansible-pool
lb_method=least_connection_member
slow_ramp_time=120
- name: プールメンバーを追加(1つ目)
local_action: >
bigip_pool
server=192.168.122.95
user=admin
password=admin
state=present
name=ansible-pool
host=192.168.150.10
port=80
- name: プールメンバーを追加(2つ目)
local_action: >
bigip_pool
server=192.168.122.95
user=admin
password=admin
state=present
name=ansible-pool
host=192.168.150.20
port=80
- name: プールメンバーを追加(3つ目)
local_action: >
bigip_pool
server=192.168.122.95
user=admin
password=admin
state=present
name=ansible-pool
host=192.168.150.30
port=80
さぁ!実行してみましょう!するとエラーが出ます。。。
とりあえず動かしてみる(失敗する編)
[daijik@centos-docker-test ~]$ ansible-playbook my_bigip_create_pool.yml
PLAY [bigip] ******************************************************************
GATHERING FACTS ***************************************************************
ok: [192.168.122.95]TASK: [Collect BIG-IP facts] **************************************************
failed: [192.168.122.95 -> 127.0.0.1] => {"failed": true}
msg: the python suds and bigsuds modules is requiredFATAL: all hosts have already failed -- aborting
PLAY RECAP ********************************************************************
to retry, use: --limit @/home/daijik/mybigip.retry192.168.122.95 : ok=1 changed=0 unreachable=0 failed=1
エラーメッセージが出ていますね。bigsuds というモジュールが必要だ、と言われています。実は bigsuds というモジュールはF5のDevCentralというコミュニティに公開されているモジュールでして、以下のサイトから入手が可能となっています。(もしかすると、DevCentralへのユーザー登録は必要かもしれません。タダです)
bigsudsのダウンロード
bigsudsのインストール
# sudo python setup.py install
bigsudsのインストールが完了したら、もう一度、試してみます。その前に、一度、BIG-IPの管理コンソールにログインをして、現在の状態を確認しておきましょう。
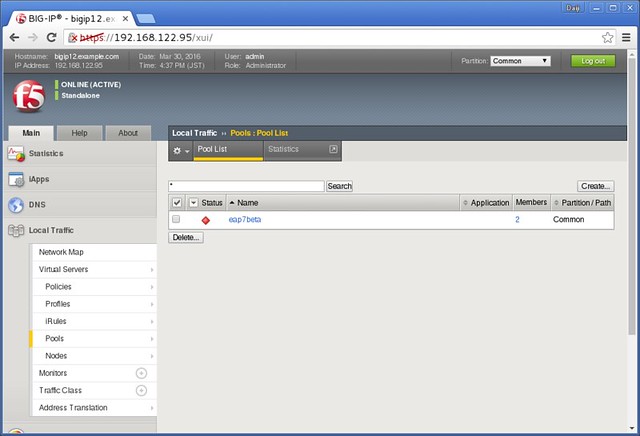
この画面は「サーバープールの一覧」を表示させています。一つ、作成済みの状態ですが、今回のテストとは関係ありませんので無視してください。この状態を初期状態とします。
さて、現在の状態も確認できたので、もう一度、ansibleでplaybookを実行します。
[daijik@centos-docker-test ~]$ ansible-playbook my_bigip_create_pool.yml
PLAY [bigip] ******************************************************************
GATHERING FACTS ***************************************************************
ok: [192.168.122.95]TASK: [プールを作成] ****************************************************
changed: [192.168.122.95 -> 127.0.0.1]TASK: [プールメンバーを追加(1つ目)] *************************
changed: [192.168.122.95 -> 127.0.0.1]TASK: [プールメンバーを追加(2つ目)] *************************
changed: [192.168.122.95 -> 127.0.0.1]TASK: [プールメンバーを追加(3つ目)] *************************
changed: [192.168.122.95 -> 127.0.0.1]PLAY RECAP ********************************************************************
192.168.122.95 : ok=5 changed=4 unreachable=0 failed=0
今度はエラーとならず、正常に実行できました。BIG-IPの管理コンソールでも見てみましょう。
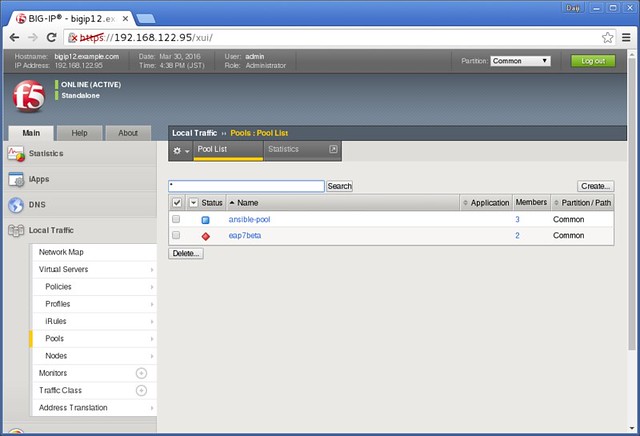
「ansible-pool」というものが作成されています。プール名をクリックすると詳細が見られます。
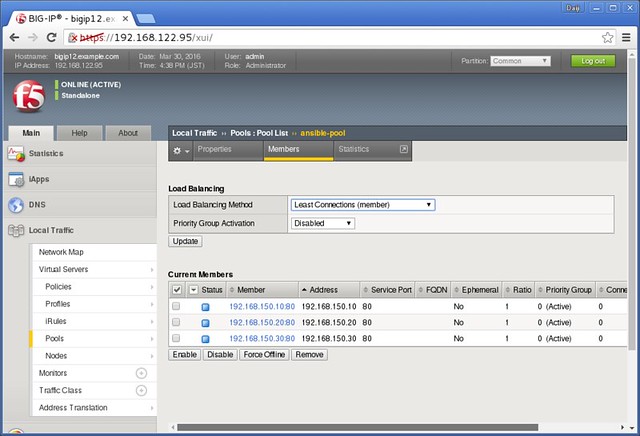
期待通り、3つのサーバーが登録されています。負荷分散のアルゴリズムもLeast Connectionになっています。期待通り、AnsibleからBIG-IPへ、設定をいれることが出来たようです。
一度、Playbookの作り方さえ覚えてしまえば、OSやミドルウェアの設定だけではなく、ネットワークの設定まで宣言的に出来て、自動化することができるので、インフラ/アプリケーションの運用担当者にとっては、かなり楽になるツールなんじゃないか、と期待できます。Ansibleは使い方が簡単なのも良いですね。
さて、最後に、今回作成したサーバープールはお掃除しておきましょう。
サーバープールの削除(my_bigip_delete_pool.yml)
---
- hosts: bigip
tasks:
- name: プールを削除
local_action: >
bigip_pool
server=192.168.122.95
user=admin
password=admin
state=absent
name=ansible-pool
そして、実行。
[daijik@centos-docker-test ~]$ ansible-playbook my_bigip_delete_pool.yml PLAY [bigip] ****************************************************************** GATHERING FACTS *************************************************************** ok: [192.168.122.95] TASK: [プールを削除] **************************************************** changed: [192.168.122.95 -> 127.0.0.1] PLAY RECAP ******************************************************************** 192.168.122.95 : ok=2 changed=1 unreachable=0 failed=0
最後に確認。
元の状態に戻りました。
まとめ
- 想定どおり、BIG-IP LTMのオブジェクトの構成管理が出来ることが確認できた。
- ただし、操作できる対象は、VIPやプールやプールメンバーといった「よく使うオブジェクトのよく使うパラメータだけ」という印象。あまり細かいところまでは手を出そうと思わないほうが良いだろう。
- 現状では、Interface / VLAN のようなシステムレベルでの設定や、ライセンス関連の操作は行うことが出来無い(モジュールとして用意されていない)ので、このあたりもマニュアルで対処する必要がありそう。
- まぁ、予想通りの結果でした(^^)v